CREATE TABLE
CREATE TABLE creates a new D3 file and an SQL mapping. For each column specified in the CREATE TABLE statement, an attribute-defining item is created.
CREATE TABLE should not be used on existing D3 files and will fail if there is a pre-existing D3 file with the same name. CREATE TABLE is not supported by transaction processing and cannot be undone.
CREATE TABLE table_name (column_element [, column_element...]) [size]
column_element ::=
column_definition
|[CONSTRAINT constraint_name] table_constraint_definition
column_definition ::=
column_name data_type [DEFAULT default_value] [column_constraint_definition
[column_constraint_definition...]]
data_type ::=
VARCHAR(length) | DECIMAL(precision, scale)
| NUMERIC(precision, scale) | SMALLINT | INTEGER
| FLOAT(precision) | DOUBLE PRECISION | REAL | DATE
column_constraint_definition ::=
NULL | NOT NULL | UNIQUE | PRIMARY KEY
table_constraint_definition ::=
UNIQUE (column_name [, column_name...])
| PRIMARY KEY (column_name [, column_name...])
| FOREIGN KEY (column_name [, column_name ...]) REFERENCES table
[(column_name [, column_name ...])]
| NESTED KEY (column_name [, column_name ...]) REFERENCES table
size ::=
MODULO modulo_number
| STORAGE (INITIAL size_in_bytes)
Creating D3 files using SQL
There may be special circumstances when it is necessary to create new D3 files using SQL syntax. The CREATE TABLE statement is provided for this purpose. Beware, however, that D3 files created by CREATE TABLE are limited to the two dimensions of an SQL table. To create D3 files with the full flexibility and power of D3, first create the D3 files utilizing D3 correlatives and then use the TCL command, SQL-CREATE-TABLE to create the SQL tables.
Primary key (syntax part)
There can be no more than one PRIMARY KEY constraint although this constraint may contain multiple columns. Although a PRIMARY KEY constraint is not required (except when the table is the parent of a nested child) one is recommended for performance reasons.
Because the items in a D3 file are unordered, one cannot select rows using their position in the file. There is no first item or last item. For faster random access to data, the database defines a primary key which allows direct access to a specific row. The method of defining a primary key varies, depending on whether the table is a standard flat table or is nested.
For flat tables (i.e., tables which do not have MultiValues or multi-subvalues), the primary key is directly associated with the D3 item-ID. The SQL-CREATE-TABLE utility performs this conversion automatically. When creating a new table, the user may manually indicate the primary key by adding the primary key (column_name) clause to the CREATE TABLE statement.
ExampleThis example creates a table called CUSTOMERS with two columns, ID and NAME, where ID is the primary key.
CREATE TABLE customers (id VARCHAR(10) PRIMARY KEY, name varchar(20))
Performing this command at the TCL command prompt on a D3 database (isql CREATE TABLE…), produces a D3 file called customers with two ADIs along with the SQL table, customers. If a CREATE TABLE is performed without a primary key, a hidden primary key is created which cannot be directly accessed by the user through SQL statements.
ExampleThis example creates a table containing a multiple column primary key.
CREATE TABLE orders(customerid VARCHAR(10), orderid varchar(20), qty integer, ship_date date, constraint ord_pks PRIMARY KEY(customerid, orderid))
Nested tables generally have a multiple column primary key. This primary key consists of the parent table’s primary key as well as one user-selected column in the nested table. If SQL-CREATE-TABLE is run, the nested primary key corresponds to the controlling attribute of a controlling/dependent set as well as the item-ID.
Using nested keys to create nested tables
The NESTED KEY clause is similar to the standard SQL FOREIGN KEY clause except that the NESTED KEY clause nests the new file structure within the rows of the parent file. This provides extremely fast access to related records and simple integrity control.
Nested tables are a set of tables that are related to one another using a parent-child relationship. Each nested child table contains a key or set of keys, called nested keys, that refers back to the parent table. This concept is identical to the standard SQL foreign key concept except that a nested key indicates that the internal storage of the nested row is within the parent row. This storage of associated rows in the same internal location can dramatically reduce both disk and CPU time required to run many SQL statements. Up to three levels of nesting are allowed.
SQL users getting started with D3 SQL who wish to use nesting should use the NESTED KEY construct in CREATE TABLE where one would normally use the FOREIGN KEY construct in a classic SQL environment. Keep in mind however, that there can be only one NESTED KEY construct, and that the parent table must have been defined previously. Further, the exact set of keys specified in the NESTED KEY construct must be duplicated in the PRIMARY KEY construct of the parent table.
For D3 users getting started with D3 SQL, it is easiest to let the SQL-CREATE-TABLE command do most of the conversions from D3 files into SQL tables. Each D3 controlling/dependent set is converted into an additional nested table with the nested key being the item-id of the parent table. See Creating SQL views and tables and Advanced use of the commands for additional information.
Example
This example shows how to build a series of nested tables corresponding to a MultiValue ORDERS file. From a MultiValue point-of-view, the table set would have structure as seen below:
| ORDERS | |||
| Order_no | Part_no | Req_ship_date | Req_ship_qty |
| Req_ship_date | Req_ship_qty | ||
| Part_no | Req_ship_date | Req_ship_qty | |
| Req_ship_date | Req_ship_qty | ||
A traditional flat point-of-view might envision several files representing the same data. Below is the flat-file representation along with the SQL statements for creating three nested tables corresponding to the data structures. These data structures are presented to SQL as three separate tables, but they are really nested using the MultiValue format for internal access.
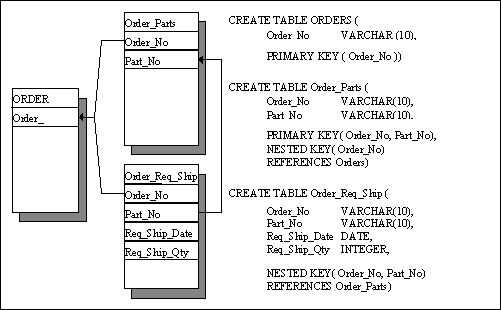
The statements below behave in special ways when dealing with nested tables.
| SELECT | A SELECT statement, when executed against a nested table, works as if that table was a standard SQL flat table. Optimization is undertaken for joins involving two or more tables nested on the same internal file. |
| DELETE | A DELETE statement, when executed on any row of a table with nested children, cascades the delete to associated rows of those nested sets. To DELETE a row in a nested table, the nested key, and if available, the pseudo column, is used to identify the specific row to be deleted. A DELETE which removes rows in a nested table that matched the nested key never deletes rows from a parent level. |
| INSERT | An INSERT statement creates only the rows for the nested level specified by the table definition. To INSERT a row in a nested table, the row in the parent table must exist. Therefore, the INSERT statement must specify pre-existing values for nested key columns for a particular nested table. It is not valid to insert a row with a null controlling column. The controlling column is the primary key column, or if no primary key is indicated, the controlling column is the first column specified in the CREATE TABLE statement. |
| UPDATE | An UPDATE statement must specify pre-existing values for nested key columns for a particular nested table. An UPDATE which does not meet this criteria fails. |