Data Paging in Web Applications
Data paging is a mechanism for grouping records retrieved from a database into discrete chunks (data pages), each one displaying a limited number of records. It limits the number of records fetched from the database, even when a large number of records match the query, thereby providing better performance.
In non-web applications, Uniface provides automatic data paging by means of stepped hitlists. By default, data is fetched in 10-record increments (although the step size is configurable). However, a stepped hit list is only possible when the client has an open connection with the persistent data server (the database). If the client requests the next set of hits, the data server knows what the last set was and can therefore return the next set.
In web applications, stepped hitlists are not possible because the client and server are disconnected. Every action on the client results in an explicit request being sent to the server, and a generated response from the server, after which the connection is lost again. To implement data paging in web applications, the retrieved dataset must have a fixed order, and each request sent to the server must specify where to start fetching the data.
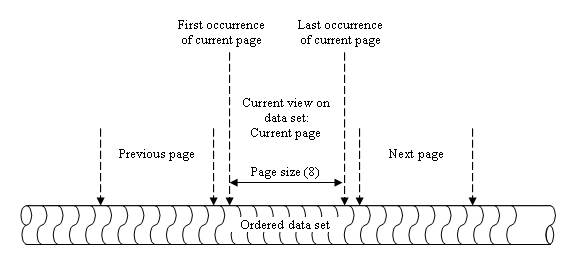
In Uniface web applications, you can use arguments of the read ProcScript statement to implement data paging:
-
The order by clause ensures that the data set has a fixed sequence.
-
The maxhits option determines the number of records fetched in each request.
-
The offset option specifies where to start fetching records, using native database functionality.
For example, the following statement fetches 10 records from a dataset that has been order by the LASTNAME field , starting at the 101st record:
read options "maxhits=10;offset=100 order by "LASTNAME"
For more information, see read .
If you cannot use the offset option, you need to implement some other way of data paging. For more information, see Example: Using Client State for Data Paging.